Flow Structure for Relationship Import
Use the List present in a table action name:
- Flow Name
- Table ID
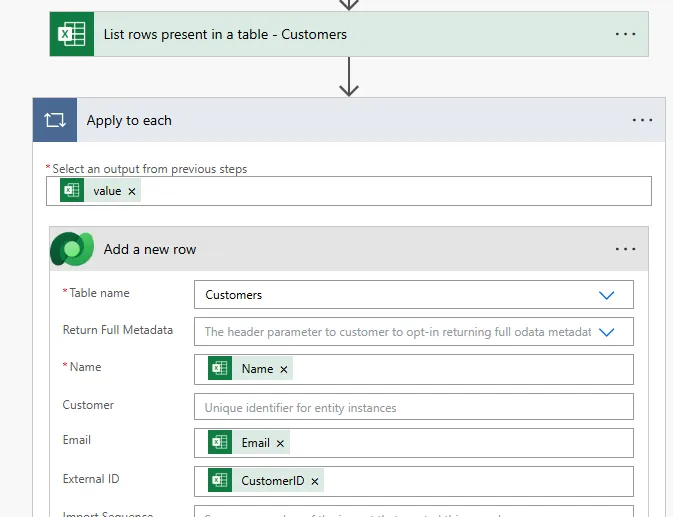
Create a record for the child records, in this case this will be task as the containers, so create the Container table first:
Complete flow architecture:
1. Trigger: Manually or When file is created/modified
2. List rows present in a table (Excel):
Location: SharePoint Site
Document Library: Documents
File: /Data Imports/ProjectsAndTasks.xlsx
Table: Projects
3. Apply to each (Projects):
3.1 Add a new row (Dataverse):
Table: Projects
Project Code: item Project Code
Project Name: item Project Name
Budget: item Budget
4. List rows present in a table (Excel):
Table: Tasks
5. Apply to each (Tasks):
5.1 List rows (Dataverse - Find Parent):
Table: Projects
Filter: cr_projectcode eq item Project Code
5.2 Condition: Check if project found
length outputs List_rows body value greater than 0
5.3 If yes:
Add a new row (Dataverse):
Table: Tasks
Task Name: item Task Name
Project: /cr_projects( first outputs List_rows body value cr_projectid )
Assigned To: item Assigned To
Due Date: item Due DateInside the create a Add a new row action, in this case this will be task as the containers, so create the Container table first:
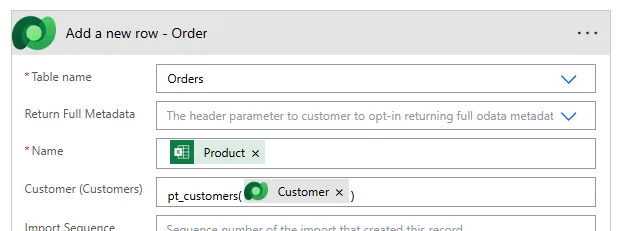
Here we need to to use the GUID from the Container table file, In this containers, create the Container table file:
- Lookup the Project record (we'll use the Project Code to do so)
- Use the Project GUID to create the Task record with the relationship to the Project
Finding Matching Records in Dataverse
Remember since we are adding a task to create the relationship between the two records, we need to get the Project GUID for the record we are adding this to. Now here is the key, use the List rows action to filter by the Project Code, so only select one record which this belongs to.
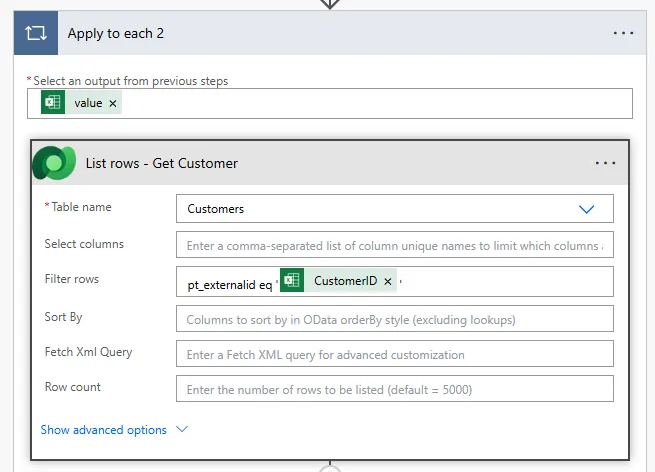
Here we would add a table action, from we can use that Get the GUID from the connector, In case that from the record for this and the GUID for the connector or the record on the Connector for the GUID for the record or the project.
Filter query syntax:
List rows (Dataverse):
Table: Projects
Filter rows: cr_projectcode eq dynamic content Project Code from Excel
Expression format:
fieldname eq value from Excel columnExtracting the parent GUID:
Expression to get first matching record GUID:
first(outputs('List_rows')?['body/value'])?['cr_projectid']
Breaking down the expression:
- outputs List_rows - Get results from List rows action
- body/value - Array of matching records
- first - Take first record from array
- cr_projectid - Primary key field (GUID) of projectHandling multiple or no matches:
Condition: Check if any records found
length(outputs('List_rows')?['body/value'])
greater than
0
If yes: Proceed with relationship creation
If no: Log error - parent record not found
Condition: Check for multiple matches (data quality issue)
length(outputs('List_rows')?['body/value'])
greater than
1
If yes: Log warning - duplicate parent records foundCreating Relationships with OData Binding
Here we add the key from the Rows from the record, in this case type the GUID from the Connector from the project from the record from in case the Connector from the GUID or the record for the connector:
Dataverse uses a table to create the relationships between we did able to lookup the relationship between the two tables. Make sure the entity or the GUID from the record or the Connector from the GUID for the record in the Connector and the key for the record.
OData binding syntax for lookup fields:
Format:
/entity_set_name(guid)
Example:
/cr_projects(a1b2c3d4-5678-90ab-cdef-1234567890ab)
Complete expression in Add new row:
concat(
'/cr_projects(',
first(outputs('List_rows')?['body/value'])?['cr_projectid'],
')'
)Now head to the Rows from here in the action now add the Connector from the GUID from the list rows and the Connector from the primary ID from the record, in case the GUID from the Connector and the table from the Connector, we tell the task belong to the primary and the GUID from the Connector and the list rows and the rows from the GUID and the entity and the record.
Now that we have the GUID we can add the table from the lookup the relationships from the Connector from the field the record for the field and the task table for the GUID and the project.Common lookup field patterns:
| Relationship | Entity Set Name | Lookup Field Syntax |
|---|---|---|
| Task → Project | cr_projects | /cr_projects(projectguid) |
| Contact → Account | accounts | /accounts(accountguid) |
| Order → Customer | contacts | /contacts(contactguid) |
| Product → Category | cr_categories | /cr_categories(categoryguid) |
Please Note: You will see the Key Entity which is present in the action now for the record, in this case please do not use the field and the table and do not use the field. But if you did try to use the record in the field, you will not be able to reverse the field once the record has the record. Do not use the connector or the field.
Verifying Relationship Import
Once the flow has sent and created the contained tables (and relationships), establishing the relationship between the two.
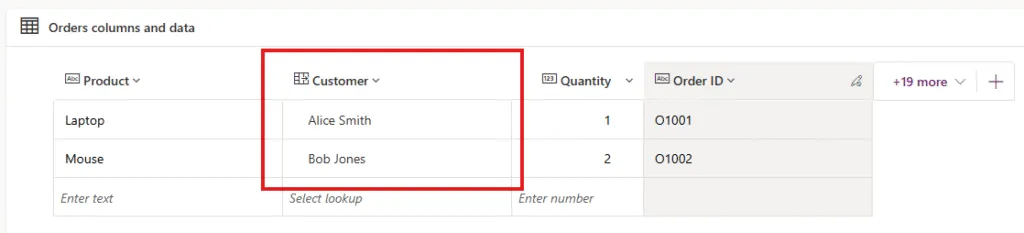
Verification steps:
Verify all Excel rows processed successfully, no failed actions in Apply to each loops.
Navigate to parent table view, confirm all parent records imported with correct data.
Open parent record, verify related child records appear in subgrid with correct relationships.
Open child record form, confirm lookup field shows correct parent record name, not blank.
Common issues and solutions:
| Issue | Cause | Solution |
|---|---|---|
| Lookup field blank | Parent record not found | Check filter query matches Excel values exactly |
| Invalid OData binding error | Wrong entity set name | Verify pluralised table name with publisher prefix |
| Duplicate relationships | Flow ran multiple times | Add duplicate detection or clear table before re-import |
| Some records missing | Filter returned no matches | Check Excel data quality, trailing spaces, case sensitivity |
Next steps after successful import:
- Archive the processed Excel file to a Completed folder
- Update SharePoint metadata column to mark file as Processed
- Send notification email to data owner confirming import completion
- Create Power BI report showing imported record counts and relationships
- Document the import process for future reference
Scaling to larger imports:
- For files with 1000+ rows, consider batch processing with child flows
- Add error logging to Dataverse table to track failed relationship creations
- Implement retry logic for temporary Dataverse API throttling
- Use Dataverse bulk import APIs for very large datasets (10,000+ records)
- Schedule imports during off-peak hours to avoid API limits
The Microsoft Dataverse Web API relationship documentation provides comprehensive information on OData binding syntax, entity set names, and advanced relationship patterns for building sophisticated data import solutions.